Real Code
Can the agent see?
Real, repository-level program information rarely enters the model's context. I inject whitebox program slices so the agent sees cross-function causal chains.
MioHint
Ph.D. Student · Computer Science
The Chinese University of Hong Kong
Advised by Prof. Michael R. Lyu
I work on agentic software engineering — building and rigorously evaluating code agents that reason over entire repositories, diagnose failures, repair programs, and learn from real execution feedback.
My research connects code large language models with classical program analysis and reinforcement learning, spanning benchmarks, agentic systems, and training methods for real, repository-level, industrial-scale software. I worked as a research intern at WeChat, where several of these systems were deployed in production.
LLM agents look capable on toy benchmarks, yet fail in real software systems at three successive stages. My work follows this causal chain and resolves each stage in turn.
Can the agent see?
Real, repository-level program information rarely enters the model's context. I inject whitebox program slices so the agent sees cross-function causal chains.
MioHint
Can the agent reason?
Even with full context, agents fail to aggregate cross-file evidence — an aggregation deficit. I diagnose it and converge scattered runtime evidence in production.
RepoReasonHolmes
Can the agent fix & learn?
Patches may compile yet be wrong, and weak execution feedback is hard to learn from. I reshape it into comparable, creditable, and learnable training signal.
ComBenchVulKeyGRPO Reshaping
Every stage of the software lifecycle leaves observations and feedback. My long-term goal is a closed-loop, self-evolving software system — where agents turn these observations into learnable signals and keep improving, cycle after cycle.
These observations become the three signals my work grounds agents in — Real Code (authentic artifacts), Real Reasoning (attributable evidence chains), and Real Reward (learnable execution feedback). I aim to generalize this signal reshaping to broad weak-feedback, long-horizon code tasks, so agents continuously self-evolve from real feedback.
First author on all listed works.
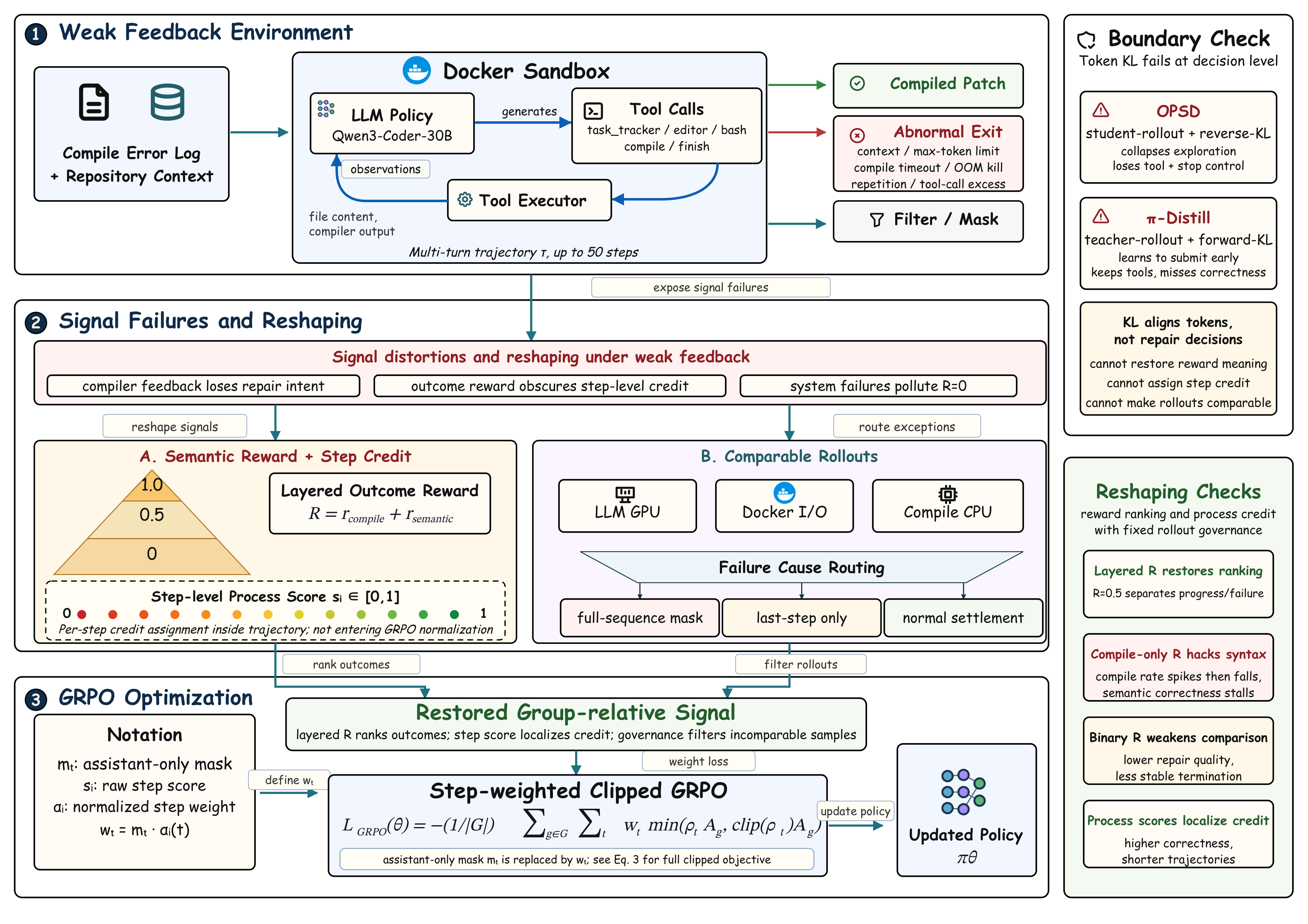
Signal Reshaping for GRPO in Weak-Feedback Agentic Code Repair
Preprint
Reframes weak-feedback multi-turn code repair as a GRPO trainability problem, using layered rewards, step-level process weighting, and failure-cause-aware rollout governance to lift two-stage repair from 0.385 to 0.535.
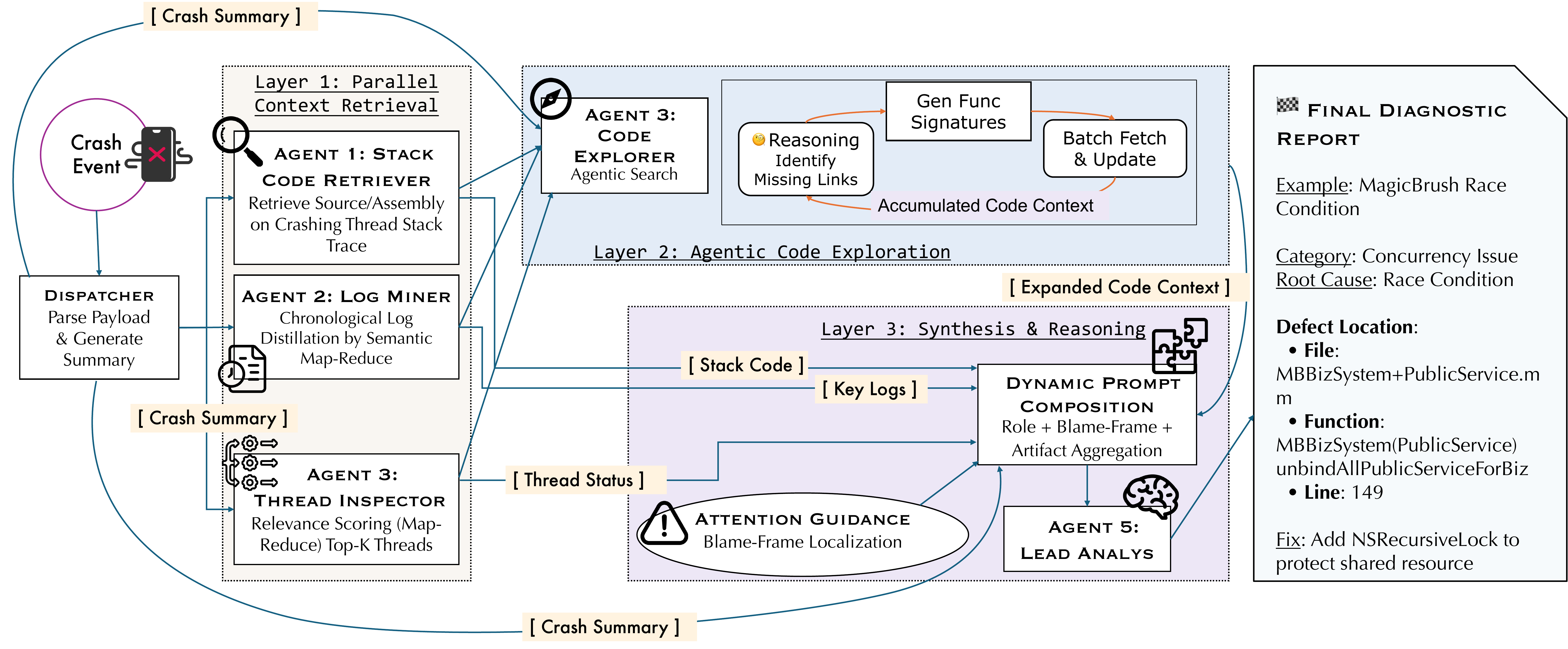
Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
FSE 2026, Industry Track
A retrieve–explore–reason multi-agent system for post-mortem mobile crash diagnosis over WeChat's mixed-language codebase, reaching 87.6% function-level localization accuracy and running ~40k times in production.
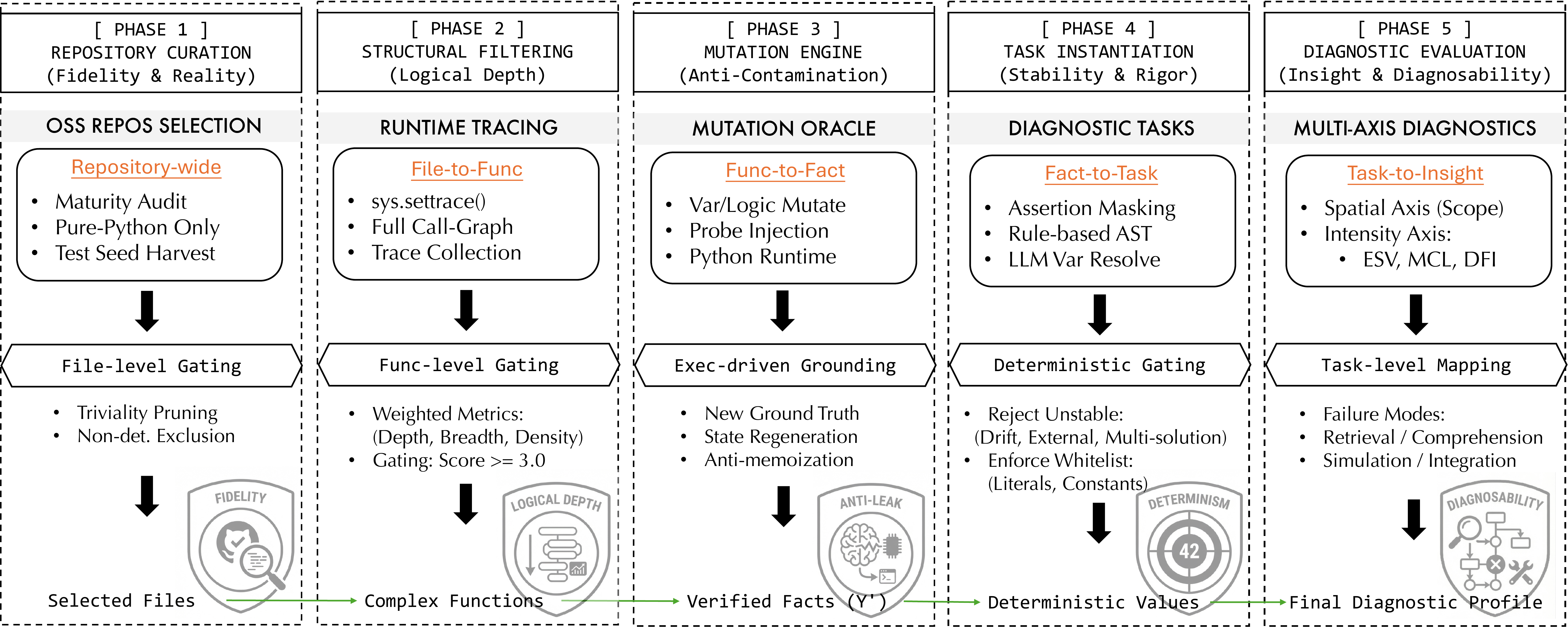
From Laboratory to Real-World Applications: Benchmarking Agentic Code Reasoning at the Repository Level
ACL 2026 Main Oral
Introduces RepoReason, a repository-level benchmark built on abductive assertion verification and execution-driven mutation, with ESV / MCL / DFI metrics that expose aggregation deficits in frontier code agents.
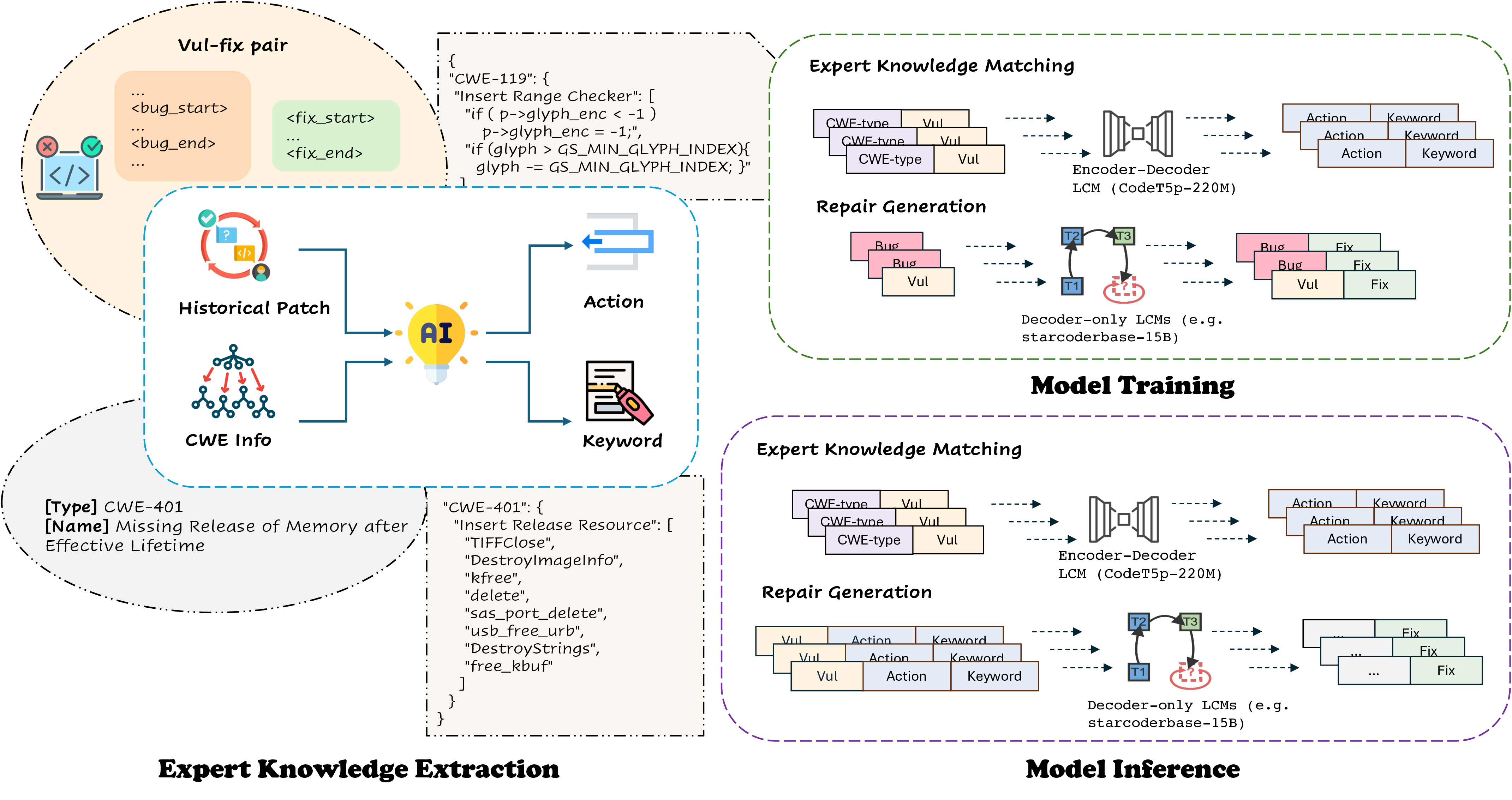
VulKey: Automated Vulnerability Repair Guided by Domain-Specific Repair Patterns
FSE 2026
Guides vulnerability repair with a three-level abstraction of CWE/NVD expert knowledge, improving PrimeVul and Vul4J accuracy across languages and models.
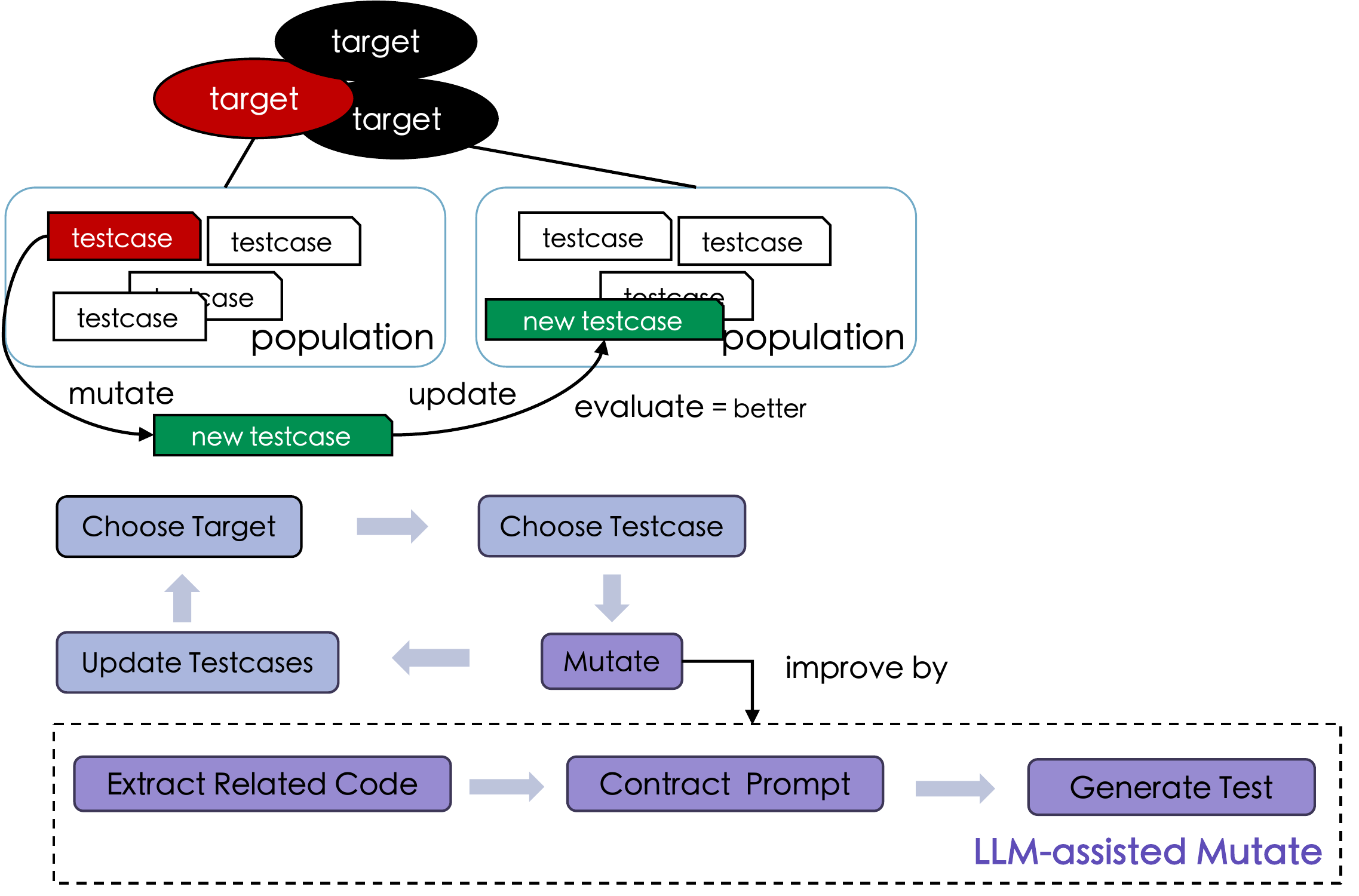
MioHint: LLM-Assisted Request Mutation for Whitebox REST API Testing
ICSE 2026
Combines statement-level def-use analysis with LLM-generated mutation hints to escape fitness plateaus in whitebox REST API testing.
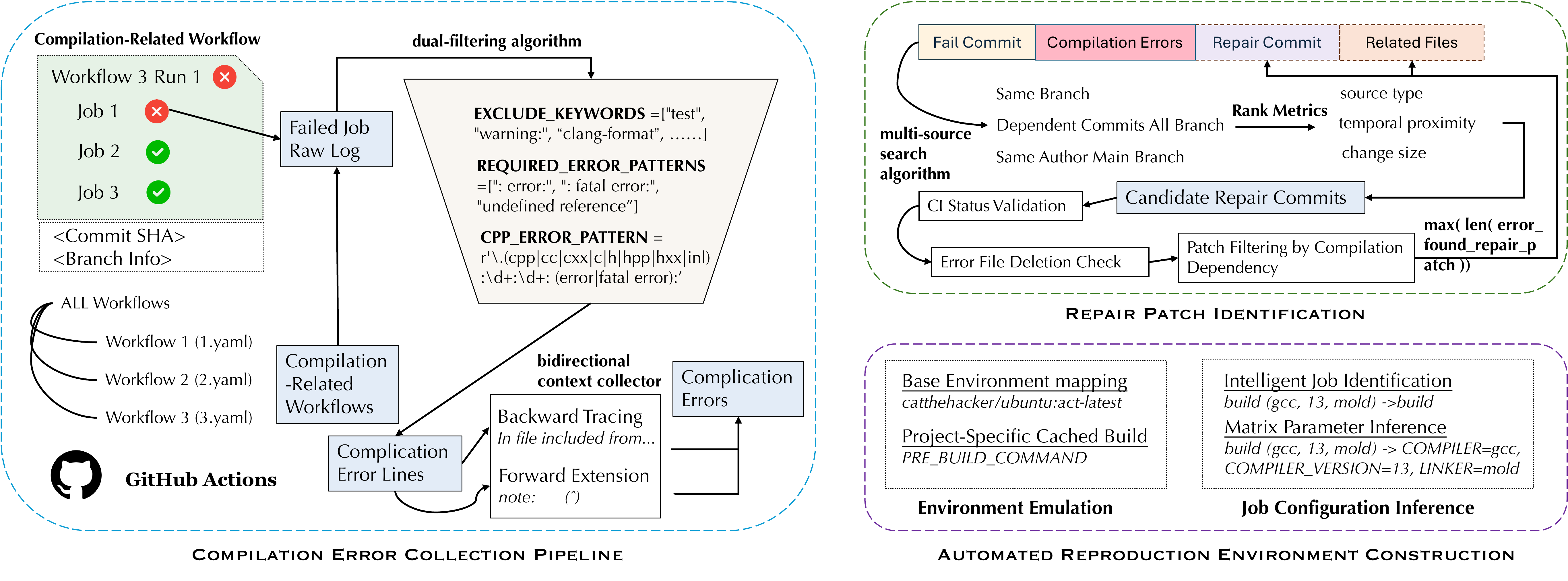
ComBench: A Repository-level Real-world Benchmark for Compilation Error Repair
Preprint
Mines and faithfully reproduces real C/C++ compilation failures from GitHub CI histories, exposing the compile-but-incorrect gap between compilable and semantically correct LLM patches.